


Assembly 数组详解
2018-10-29 12:00 更新
一组数组是内存中的一个连续数据列表块。在这个列表中的每个元素必须是同一种类型而且使用恰好同样大小的内存字节来储存。因为这些特性,数组允许通过数据在数组里的位置(或下标)来对它进行有效的访问。如果知道了下面三个细节,任何元素的地址都可以计算出来:
1、数组第一个元素的地址
2、每个元素的字节数
3、这个元素的下标
0(正如在C中)作为数组的第一个元素的下标是非常方便的。使用其它值作为第一个下标也是可能的,但是这将把计算弄得很复杂。
定义数组
在data和bss段中定义数组
在data段定义一个初始化了的数组,可以使用标准的db,dw,等等指示符。NASM同样提供了一个有用的指示符,称为TIMES ,它可以用来反复重复一条语句,而不需要你手动来复制它。图5.1展示关于这些的几个例子。
在bss段定义一个示初始化的数组,可以使用resb,resw,等等指示符。记住,这些指示符包含一个指定保留多少个内存单元的操作数。图5.1同样展示了关于这种类型定义的几个例子。

以局部变量的方式在堆栈上定义数组
在堆栈上定义一个局部数组变量没有直接的方法。像以前一样,你可以首先计算出所有局部变量需要的全部字节,包括数组,然后再用ESP减去这个数值(或者直接使用ENTER指令)。例如,如果一个函数需要一个字符变量,两个双字整形和一个包含50个元素的字数组,你将需要1+2+4+50X2 = 109个字节。但是,为了保持ESP在双字的边界上,被ESP减的数值必须是4的倍数(这个例子中是112。)图5.2展示了两种可能的方法。第一种排序的未使用部分用来保持双字在双字边界上,这样可以加速内存的访问。

访问数组中的元素
跟C不同的是,在汇编语言中没有[ ]运算符。要访问数组中的一个元素,必须将它的地址计算出来。考虑下面两个数组的定义:
array1 db 5, 4, 3, 2, 1 ; 字节数组
array2 dw 5, 4, 3, 2, 1 ; 字数组
下面是使用这些数组的例子:
1 mov al, [array1] ; al = array1[0]
2 mov al, [array1 + 1] ; al = array1[1]
3 mov [array1 + 3], al ; array1[3] = al
4 mov ax, [array2] ; ax = array2[0]
2 mov al, [array1 + 1] ; al = array1[1]
3 mov [array1 + 3], al ; array1[3] = al
4 mov ax, [array2] ; ax = array2[0]
5 mov ax, [array2 + 2] ; ax = array2[1] (不是array2[2]!)
6 mov [array2 + 6], ax ; array2[3] = ax
7 mov ax, [array2 + 1] ; ax = ??
6 mov [array2 + 6], ax ; array2[3] = ax
7 mov ax, [array2 + 1] ; ax = ??
在第5行,引用了字数组中的元素1,而不是元素2。为什么?因为字是两个字节的单元,所以移动到字数组的下一元素,你必须向前移动两个字节,而不是一个。第7行将从第一个元素中读取一个字节再从第二个元素中读取一个字节。在C中,编译器会根据一个指针的类型来决定使用指针运算的表达式需移动多少字节,而程序员就不需要管这些了。然而,在汇编语言中,当需要从一个元素移动到另一个元素时,它取决于程序员认为的数组元素的大小。

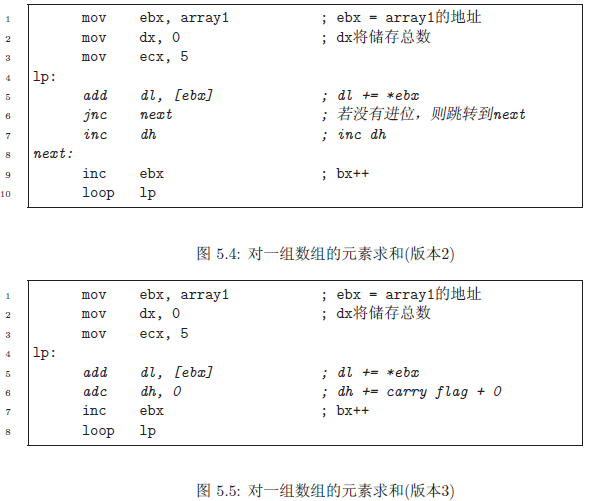
图5.3展示了一个代码片段:对前面样例代码中的数组array1中的元素进行了求和。第7行,AX与DX相加。为什么不是AL?首先,ADD指令的两个操作数必须为同样的大小。其次,这样做对于对字节求和后得到一个太大以致不能匹配一个字节的总数是非常容易的。通过使用DX,达到65,535的总数是允许。然而,认识到AH同样被相加了是非常重要的。这
就是第3行为什么AH被置为0的缘故了。1
就是第3行为什么AH被置为0的缘故了。1
图5.4和图5.5展示了两种可以替换的方法来计算总数。斜体字的行替换了图5.3中的第6行和第7行。
以上内容是否对您有帮助:

更多建议: