

之前小编的一篇文章pytorch 计算图以及backward,讲了一些pytorch中基本的反向传播,理清了梯度是如何计算以及下降的,建议先看懂那个,然后再看这个。
从一个错误说起:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed
在深度学习中,有些场景需要进行两次反向,比如Gan网络,需要对D进行一次,还要对G进行一次,很多人都会遇到上面这个错误,这个错误的意思就是尝试对一个计算图进行第二次反向,但是计算图已经释放了。
其实看简单点和我们之前的backward一样,当图进行了一次梯度更新,就会把一些梯度的缓存给清空,为了避免下次叠加,但在Gan这种情形下,我们必须要二次更新,那怎么办呢。
有两种方案:
方案一:
这是网上大多数给出的解决方案,在第一次反向时候加入一个l2.backward(),这样就能避免释放掉了。
方案二:
上面的方案虽然解决了问题,但是并不优美,因为我们用Gan的时候,D和G两者的更新并无联系,二者的联系仅仅是D里面用到了G的输出,而这个输出一般我们都是直接拿来用的,而问题就出现在这里。
下面给一个模拟:
data = torch.randn(4,10)
model1 = torch.nn.Linear(10,2)
model2 = torch.nn.Linear(2,2)
optimizer1 = torch.optim.Adam(model1.parameters(), lr=0.001,betas=(0.5, 0.999))
optimizer2 = torch.optim.Adam(model2.parameters(), lr=0.001,betas=(0.5, 0.999))
loss = torch.nn.CrossEntropyLoss()
data = torch.randn(4,10)
label = torch.Tensor([0,1,1,0]).long()
for i in range(20):
a = model1(data)
b = model2(a)
l1 = loss(a,label)
l2 = loss(b,label)
optimizer2.zero_grad()
l2.backward()
optimizer2.step()
optimizer1.zero_grad()
l1.backward()
optimizer1.step()
上面定义了两个模型,而model2的输入是model1的输出,而更新的时候,二者都是各自更新自己的参数,并无联系,但是上面的代码会报一个RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed 这样的错,解决方案可以是l2.backward(retain_graph=True)。
除此之外我们还可以是b = model2(a.detach()),这个就优美一点,a.detach()和a的区别你可以打印出来看一下,其实a.detach()是没有梯度的,所以相当于一个单纯的数字,和model1就脱离了联系,这样model2和model1就是完全分离开来的两个图,但是如果用的是a则model2和model1则仍然公用一个图,所以导致了错误。
可以看下面示意图(这个是我猜测,帮助理解):
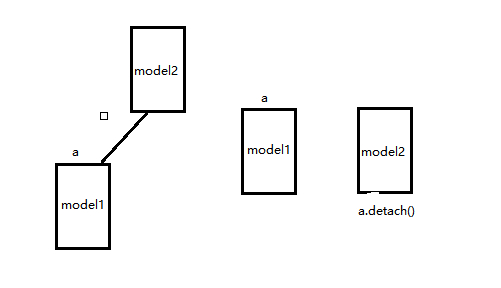
左边相当于直接用a而右边则用a.detach(),类似的在Gan网络里面D的输入可以改为G的输出y_fake.detach()。
但有一点需要注意的是,两个网络一定没有需要共同更新的 ,假如上面的optimizer2 = torch.optim.Adam(itertools.chain(model1.parameters(),model2.parameters()), lr=0.001,betas=(0.5, 0.999)),则还是用retain_graph=True保险,因为.detach则model2反向不会传播到model1,导致不对model1里面参数更新。
补充:聊聊Focal Loss及其反向传播
我们都知道,当前的目标检测(Objece Detection)算法主要分为两大类:two-stage detector和one-stage detector。two-stage detector主要包括rcnn、fast-rcnn、faster-rcnn和rfcn等,one-stage detector主要包括yolo和ssd等,前者精度高但检测速度较慢,后者精度低些但速度很快。
对于two-stage detector而言,通常先由RPN生成proposals,再由RCNN对proposals进行Classifcation和Bounding Box Regression。这样做的一个好处是有利于样本和模型之间的feature alignment,从而使Classification和Bounding Box Regression更容易些;此外,RPN和RCNN中存在正负样本不均衡的问题,RPN直接限制正负样本的比例为1:1,对于固定的rpn_batch_size,正样本不足的情况下才用负样本来填充,RCNN则是直接限制了正负样本的比例为1:3或者采用OHEM。
对于one-stage detector而言,样本和模型之间的feature alignment只能通过reception field来实现,且直接通过回归方式进行预测,存在这严重的正负样本数据不均衡(1:1000)的问题,负样本的比例过高,占据了loss的绝大部分,且大多数是容易分类的,这使得模型的训练朝着不希望的方向前进。作者认为这种数据的严重不均衡是造成one-stage detector精度低的主要原因,因此提出Focal Loss来解决这一问题。
通过人工控制正负样本比例或者OHEM能够一定程度解决数据不均衡问题,但这两种方法都比较粗暴,采用这种“一刀切”的方式有可能把一些hard examples忽略掉。因此,作者提出了一种新的损失函数Focal Loss,不忽略任何样本,同时又能让模型训练时更加专注在hard examples上。简单说明下Focal loss的原理。
Focal Loss是在标准的交叉熵损失的基础上改进而来。以二分类为例,标准的交叉熵损失函数为

针对类别不均衡,针对对不同类别对loss的贡献进行控制即可,也就是加一个控制权重αt,那么改进后的balanced cross entropy loss为
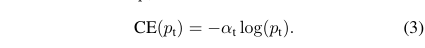
但是balanced cross entropy loss没办法让训练时专注在hard examples上。实际上,样本的正确分类概率pt越大,那么往往说明这个样本越易分。所以,最终的Focal Loss为
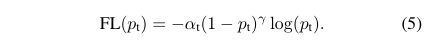
Focal Loss存在这两个超参数(hyperparameter),不同的αt和γ,对于的loss如Figure 1所示。从Figure 4, 我们可以看到γ的变化对正(forground)样本的累积误差的影响并不大,但是对于负(background)样本的累积误差的影响还是很大的(γ=2时,将近99%的background样本的损失都非常小)。


接下来看下实验结果,为了验证Focal Loss,作者提出了一种新的one-stage detector架构RetinaNet,采用的是resnet_fpn,同时scales增加到15个,如Figure 3所示
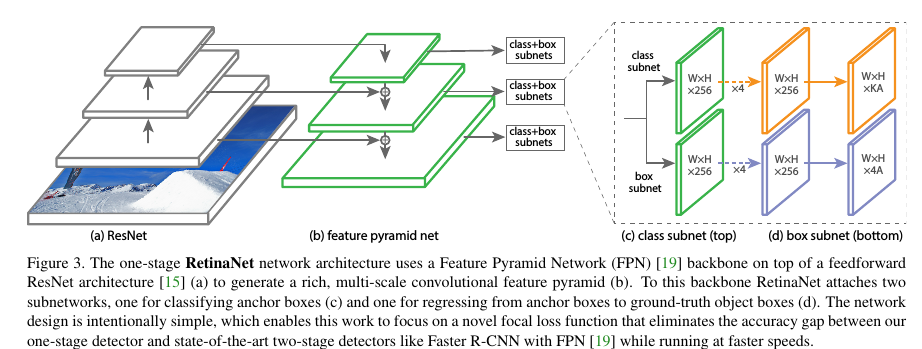
Table 1给出了RetinaNet和Focal Loss的一些实验结果,从中我们看出增加α-类别均衡,AP提高了0.9,再增加了γ控制,AP达到了37.8.Focal Local相比于OHEM,AP提高了3.2。从Table 2可以看出,增加训练时间并采用scale jitter,AP最终那达到39.1。


Focal Loss的原理分析和实验结果至此结束了,那么,我们接下来看下Focal Loss的反向传播。首先给出Softmax Activation的反向梯度传播公式,为

有了Softmax Activation的反向梯度传播公式,根据链式法则,Focal Loss的反向梯度传播公式为

总结:
Focal Loss主要用于解决数据不均衡问题,可以看做是OHEM算法的延伸。作者是将Focal Loss用于one-stage detector,但实际上这种解决数据不均衡的方法对于two-stage detector来讲同样有效。
以上就是pytorch中基本的反向传播的全部内容,希望能给大家一个参考,也希望大家多多支持W3Cschool。如有错误或未考虑完全的地方,望不吝赐教。



