

我发现自己在与许多 PostgreSQL 用户,尤其是新手用户讨论和解释sychronous_commit。所以,我想把所有的关键点记下来作为一篇博文,这对更多的用户会有用。最近我有机会在我们的 PostgreSQL Percona Tech Days 中谈论一些相关主题。
sychronous_commit 是什么?
这是我们可以决定何时可以向客户端确认事务提交成功的参数。
因此,此参数不仅与同步备用有关,而且具有更广泛的含义和含义,这对于独立的 PostgreSQL 实例也很有用。为了更好地理解,我们应该查看整个 WAL 记录传播以及可以接受提交确认的各个阶段。这使我们可以为每个事务选择不同级别的持久性。持久性选择越少,确认越快,从而提高系统的整体吞吐量和性能。
WAL 传播
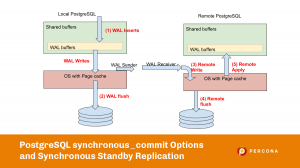
PostgreSQL WAL(Write Ahead Log)是主端更改/活动的记录,可以被视为数据库中发生的更改的日志/分类帐。下图展示了本地主PostgreSQL实例和远程热备实例中WAL传播的流程。

PostgreSQL 使用内部函数 pg_pwrite() 写入 WAL 段,该函数内部使用write()系统调用,该系统调用不保证将数据刷新到磁盘。为了完成刷新,另一个函数 issue_xlog_fsync() 被调用,它根据参数 (GUC) 发出适当类型的 fsync:wal_sync_method
上图显示了所有 5 个主要阶段。
- WAL 记录插入(本地):WAL 记录首先在 WAL 缓冲区中创建。由于多个后端进程将同时创建 WAL 记录,因此它受到锁的适当保护。wal_buffers 中 WAL 记录的写入被不同的后台进程连续写入 WAL 段。如果 sychronous_commit 完全关闭,刷新将不会立即发生,而是依赖于 wal_writer_delay 设置,我们将在下一节中讨论。
- WAL 写入和 WAL 刷新(本地):这种刷新到本地磁盘上的 WAL“段文件”被认为是繁重的操作之一。PostgreSQL 在这方面做了很多优化,以避免频繁的flush。
- 远程写入: WAL 记录写入远程备用数据库(但尚未刷新)。数据可能会在页面缓存中保留一段时间。除非我们想解决 Primary 和 Standby 实例同时崩溃的情况,否则可以考虑这种级别的持久性保护。
- Remote Flush:在这个阶段,数据真正在远程备端写入并刷新到磁盘。所以我们可以保证数据在备用端可用,即使它也会崩溃。
- 远程应用:在此阶段,WAL 记录在远程/备用端重放,可供在那里运行的会话使用。
synchronous_commit 对应的接受值如下:
- off: 您可以使用值 off、0(零)、false 或 no 来关闭 synchronous_commit。顾名思义,提交确认可以在将记录刷新到磁盘之前出现。这通常称为异步提交。如果 PostgreSQL 实例崩溃,最后几次异步提交可能会丢失。
- 本地: WAL 记录被写入并刷新到本地磁盘。在这种情况下,将在本地 WAL 写入和 WAL 刷新完成后确认提交。
- remote_write: WAL 记录成功地移交给远程实例,该实例确认了写入(不刷新)。
- on:这是默认值,您可以使用 on、true、yes 或 1 将值设置为“on”。但是含义可能会根据您是否有同步待机而改变。如果有同步待机,将值设置为 on 将导致等待直到“远程刷新”。
- remote_apply: 这将导致提交等待,直到来自当前同步备用数据库的回复表明他们已收到事务的提交记录并应用它,以便它对备用数据库上的查询可见。
通过为参数选择适当的值,我们可以选择确认何时返回。如果没有同步备用( synchronous_standby_names 为空), synchronous_commit 到 on、remote_apply、remote_write 和 local 的设置都提供相同的同步级别:事务提交只等待本地刷新到磁盘。
该领域的常见问题之一是:
“如果我们选择完全异步提交(synchronous_commit = off),我们会丢失多少数据?”
答案有点复杂,它取决于 wal_writer_delay 设置。默认为 200 毫秒。这意味着WAL 将在每个wal_writer_delay 中 刷新到磁盘。WAL 编写器会定期唤醒并调用 XLogBackgroundFlush()。这会检查完全填充的 WAL 页面。如果它们可用,它会写入到该点的所有缓冲区。所以在良好的负载条件下,WAL 写入器写入整个缓冲区。在找不到完整页面的低负载情况下,将刷新上次异步提交之前的所有内容。
如果超过 wal_writer_delay 已经过去,或者自上次刷新以来已经写入了超过 wal_writer_flush_after 块,则 WAL 被刷新到当前位置。这种安排保证异步提交记录在事务完成后最多两次 wal_writer_delay 后到达磁盘。但是,PostgreSQL 以灵活的方式写入/刷新完整缓冲区,这是为了减少每个 WAL 写入器周期填充多个 WAL 页时在高负载下发出的写入次数。从概念上讲,这会使最坏情况的延迟达到三个wal_writer_delay 周期。
所以答案很简单,就是:
在大多数情况下,损失将小于 wal_writer_delay 的两倍。但在最坏的情况下,它可能高达三倍。
设置范围
当我们讨论参数及其值时,许多用户会考虑在实例级别进行全局设置。但是,真正的力量和用法是在不同级别适当地确定范围时才出现的。在实例级别更改它是不可取的。
除了各种值之外,PostgreSQL 还允许我们在不同范围内进行此设置。
在每个事务级别在完美调整的应用程序设计中,特定事务可以为每个事务选择特定的 sychronous_commit 级别,例如:
SQL:
SET LOCAL synchronous_commit = 'remote_write';请注意“本地”规范。一旦事务块完成(提交或回滚),设置将恢复到适用于会话级别的设置。这允许架构师选择加入特定关键事务的额外开销。
在会话级别可以在每个会话级别指定设置,以便它适用于整个会话,除非被上述事务级别设置覆盖。
SQL:
SET synchronous_commit = 'remote_write';此外,您可能会选择将此作为应用程序连接中的连接字符串选项的一部分传递给 PostgreSQL。例如: "host=hostname user=postgres ... options='-c synchronous_commit=off'" 。因此可以减少任何代码修改的要求。
在用户级别在一个理想的系统中,拥有良好管理的用户帐户,每个用户帐户都将处理特定的功能。它的范围可以从关键交易系统到报告用户帐户。例如:
SQL:
ALTER USER trans_user SET synchronous_commit= ON;
ALTER USER report_user SET synchronous_commit=OFF;默认情况下,这些用户创建的会话将具有这些设置。可以在会话级别或事务级别覆盖此用户级别设置。
在数据库级别当我们有专门的系统用于报告或临时登台信息时,在数据库级别指定非常有用。
SQL:
ALTER DATABASE reporting SET synchronous_commit=OFF;在实例级别这是在 PostgreSQL 实例级别,如下所示:
SQL:
ALTER SYSTEM SET synchronous_commit=OFF;
SHOW synchronous_commit;常见用例
迁移:当发生迁移时,跨系统移动大量数据是很常见的,正确选择 synchronous_commit 甚至关闭它对于减少整体迁移时间具有重要价值。
数据加载:在数据仓库系统/报告系统中,可能会发生大量数据加载,关闭 synchronous_commit 将通过减少重复刷新的开销来大幅提升。
审计和日志记录:即使在具有关键事务的关键系统中,在确认提交之前,在备用端上也只有事务的特定部分可能是非常关键的——这是企业希望可用的。但是会有关联的日志和审计信息记录。非常有选择性地选择同步备用提交可以产生非常高的好处。
最后一点
使用 pgbench 的快速测试可以帮助验证特定环境中不同级别的提交同步的开销。总体而言,随着同步要求级别的提高,我们应该预期性能会下降。fsync 到本地磁盘的延迟、网络延迟、备用服务器上的负载、备用服务器上的争用、整体复制量、备用服务器上的磁盘性能等环境因素都会影响开销和性能。
与 fsync 不同,即使完全关闭 synchronous_commit 也不会导致数据库损坏。了解整体 WAL 传播可以帮助您从pg_stat_replication视图了解复制延迟和信息。
系统的性能就是在不牺牲真正重要的东西的情况下消除不需要的、可避免的开销。我见过一些 PostgreSQL 的超级用户,他们通过非常有效和有选择地使用 synchronous_commit 功能,为PostgreSQL 数据库提供了一个经过良好调优的系统。我希望这篇文章能帮助那些仍然没有使用它并正在寻找更高性能或耐用性的微调机会的人



