

随着近些年python大火,很多人有或多或少学习过一点python,而爬虫的技术又相对比较简单,这就导致了很多学有小成的爬虫开发者待着自己的爬虫在你的网站上爬取数据,对于大站而言,一些小小的爬虫并不会太多地影响他站点的运营。但小站就不一样了,轻则影响其他人的服务效果,重则爬虫掏干净了你的库,然后你的创作就不值钱了,那么作为一个站长,怎么进行python爬虫反爬呢?其实有一个比较简单的操作——使用http2.0。
一、前言
一个非常强的反爬虫方案 —— 禁用所有 HTTP 1.x 的请求!
现在很多爬虫库其实对 HTTP/2.0 支持得不好,比如大名鼎鼎的 Python 库 —— requests,到现在为止还只支持 HTTP/1.1,啥时候支持 HTTP/2.0 还不知道。
Scrapy 框架最新版本 2.5.0(2021.04.06 发布)加入了对 HTTP/2.0 的支持,但是官网明确提示,现在是实验性的功能,不推荐用到生产环境,原文如下:
“HTTP/2 support in Scrapy is experimental, and not yet recommended for production environments. Future Scrapy versions may introduce related changes without a deprecation period or warning.
”
插一句,Scrapy 中怎么支持 HTTP/2.0 呢?在 settings.py 里面换一下 Download Handlers 即可:
DOWNLOAD_HANDLERS = {
'https': 'scrapy.core.downloader.handlers.http2.H2DownloadHandler',
}当前 Scrapy 的 HTTP/2.0 实现的已知限制包括:
- 不支持 HTTP/2.0 明文(h2c),因为没有主流浏览器支持未加密的 HTTP/2.0。
- 没有用于指定最大帧大小大于默认值 16384 的设置,发送更大帧的服务器的连接将失败。
- 不支持服务器推送。
- 不支持
bytes_received和headers_received信号。
关于其他的一些库,也不必多说了,对 HTTP/2.0 的支持也不好,目前对 HTTP/2.0 支持得还可以的有 hyper 和 httpx,后者更加简单易用一些。
二、反爬虫
所以,你想到反爬虫方案了吗?
如果我们禁用所有的 HTTP/1.x 的请求,是不是能通杀掉一大半爬虫?requests 没法用了,Scrapy 除非升级到最新版本才能勉强用个实验性版本,其他的语言也不用多说,也会杀一大部分。
而浏览器对 HTTP/2.0 的支持现在已经很好了,所以不会影响用户浏览网页的体验。
三、措施
那就让我们来吧!
这个怎么做呢?其实很简单,在 Nginx 里面配置一下就好了,主要就是加这么个判断就行了:
if ($server_protocol !~* "HTTP/2.0") {
return 444;
}就是这么简单,这里 $server_protocol 就是传输协议,其结果目前有三个:HTTP/1.0、HTTP/1.1 和 HTTP/2.0,另外判断条件我们使用了 !~* ,意思就是不等于,这里的判断条件就是,如果不是 HTTP/2.0,那就直接返回 444 状态码,444
一般代表 CONNECTION CLOSED WITHOUT RESPONSE,就是不返回任何结果关闭连接。
我的服务是在 Kubernetes 里面运行的,所以要加这个配置还得改下 Nginx Ingress 的配置,不过还好 https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/ 预留了一个配置叫做 nginx.ingress.kubernetes.io/server-snippet,利用它我们可以自定义 Nginx 的判定逻辑。
官方用法如下:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/server-snippet: |
set $agentflag 0;
if ($http_user_agent ~* "(Mobile)" ){
set $agentflag 1;
}
if ( $agentflag = 1 ) {
return 301 https://m.example.com;
}
所以这里,我们只需要改成刚才的配置就好了:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/server-snippet: |
if ($server_protocol !~* "HTTP/2.0") {
return 444;
}
大功告成!
配置完成了,示例网站是:https://spa16.scrape.center/
我们在浏览器中看下效果:
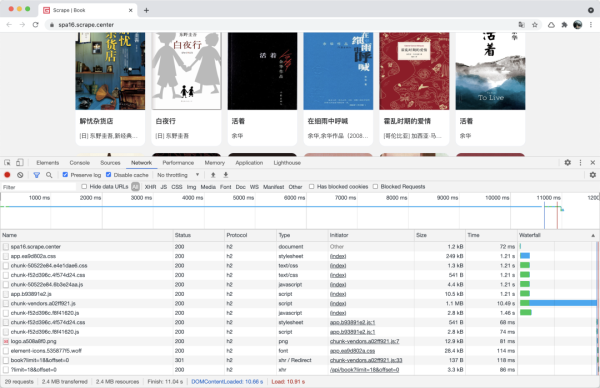
可以看到所有请求都是走的 HTTP/2.0,页面完全正常加载。
然而,我们使用 requests 来请求一下:
import requests
response = requests.get('https://spa16.scrape.center/')
print(response.text)
非常欢乐的报错:
Traceback (most recent call last):
...
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
...
raise MaxRetryError(_pool, url, error or ResponseError(cause))
requests.packages.urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='spa16.scrape.center', port=443): Max retries exceeded with url: / (Caused by ProxyError('Cannot connect to proxy.', RemoteDisconnected('Remote end closed connection without response')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
...
requests.exceptions.ProxyError: HTTPSConnectionPool(host='spa16.scrape.center', port=443): Max retries exceeded with url: / (Caused by ProxyError('Cannot connect to proxy.', RemoteDisconnected('Remote end closed connection without response')))
如果你用 requests,无论如何都不行的,因为它就不支持 HTTP/2.0。
那我们换一个支持 HTTP/2.0 的库呢?比如 httpx,安装方法如下:
pip3 install 'httpx[http2]'
注意,Python 版本需要在 3.6 及以上才能用 httpx。
安装好了之后测试下:
import httpx
client = httpx.Client(http2=True)
response = client.get('https://spa16.scrape.center/')
print(response.text)
结果如下:
<!DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="width=device-width,initial-scale=1"><meta name=referrer content=no-referrer><link rel=icon href=/favicon.ico><title>Scrape | Book</title><link href=/css/chunk-50522e84.e4e1dae6.css rel=prefetch><link href=/css/chunk-f52d396c.4f574d24.css rel=prefetch><link href=/js/chunk-50522e84.6b3e24aa.js rel=prefetch><link href=/js/chunk-f52d396c.f8f41620.js rel=prefetch><link href=/css/app.ea9d802a.css rel=preload as=style><link href=/js/app.b93891e2.js rel=preload as=script><link href=/js/chunk-vendors.a02ff921.js rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet></head><body><noscript><strong>We're sorry but portal doesn't work properly without JavaScript enabled. Please enable it to continue.</strong></noscript><div id=app></div><script src=/js/chunk-vendors.a02ff921.js></script><script src=/js/app.b93891e2.js></script></body></html>
可以看到,HTML 就成功被我们获取到了!这就是 HTTP/2.0 的魔法!
我们如果把 http2 参数设置为 False 呢?
import httpx
client = httpx.Client(http2=False)
response = client.get('https://spa16.scrape.center/')
print(response.text)
一样很不幸:
Traceback (most recent call last): ... raise RemoteProtocolError(msg) httpcore.RemoteProtocolError: Server disconnected without sending a response. The above exception was the direct cause of the following exception: ... raise mapped_exc(message) from exc httpx.RemoteProtocolError: Server disconnected without sending a response.
所以,这就印证了,只要 HTTP/1.x 通通没法治!可以给 requests 烧香了!
又一个无敌反爬虫诞生了!各大站长们,安排起来吧~
到此这篇通过如何禁用Requests库请求的方式来进行python爬虫反爬对方文章就介绍到这里,更多Python反爬虫相关技术内容请搜索W3Cschool以前的文章或继续浏览下面的相关文章。



