

今天给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固,所以除了抓包之外,还需要对 APP 进行查壳脱壳反编译等操作。
所需设备和环境:
设备:安卓手机
抓包:
fiddler+xposed+JustTrustme
查壳:ApkScan-PKID
脱壳:frida-DEXDump
反编译:jadx-gui
hook:frida
抓包
手机安装app,设置好代理,打开 fiddler 先来抓个包,发现这个 app 做了证书验证,fiddler 开启之后 app提示连接不到服务器:

那就是 app 做了 SSL pinning 证书验证,解决这种问题一般都是安装 xposed 框架,里面有一个 JustTrustme 模块,它的原理就是hook,直接绕过证书验证类,安装方法大家百度吧。
之后再打开app,可以看到成功抓到了包:
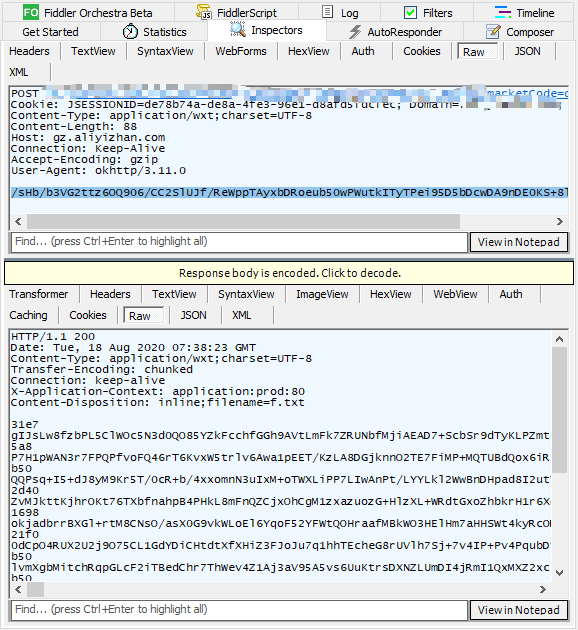
先简单分析一下,可以看到请求体中 formdata 是密文,响应内容也是密文,这个请求和响应中有用信息非常少,甚至都不知道在 jadx-gui 里怎么搜索,请求体中 formdata 是以两个等号结尾的,应该是个 base64 编码,其他一概不知。。。
脱壳反编译
那先来反编译,在这之前,通常是先用查壳工具检查一下 app 是否加固,打开 ApkScan-PKID ,把 app
可以看到这个 app 使用了 360 加固,真是层层设限啊!!这里使用frida-DEXDump来脱壳,可以到 github 上下载 frida-DEXDump 的源代码,完成之后打开项目所在文件夹,在当前位置打开命令行运行以下命令:
python main.py
等待脱壳完成,可以看到当前项目中生成了一个对应文件夹,里面有很多dex文
下面用 jadx-gui 打开 dex 文件,一般先从最大的文件开始依次搜索关键字,我们知道 java 中使用 base64 是有 BASE64Encoder 关键字的,因为抓包得到的信息非常少,在这里就只能搜索这个关键字了,搜到第四个dex中,得到了疑似加密处:
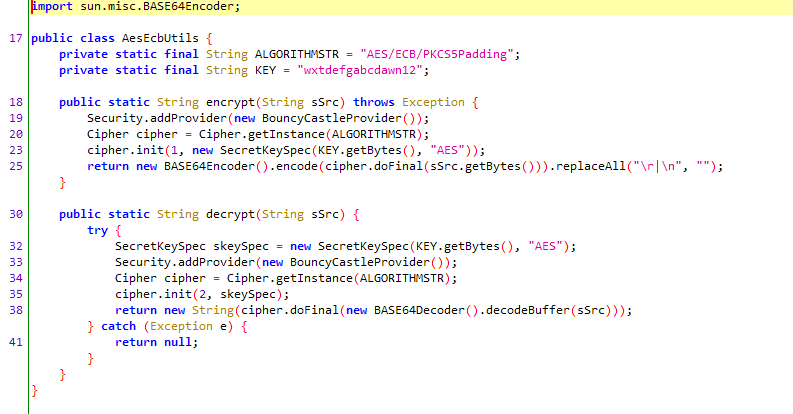
可以看到是使用了一个 aes 加密,密钥是固定的字符串。
Frida Hoo
Java不太熟,分析不来,直接使用 frida 来写一段 hook 代码看一看 encrypt 函数入参和出参的内容:
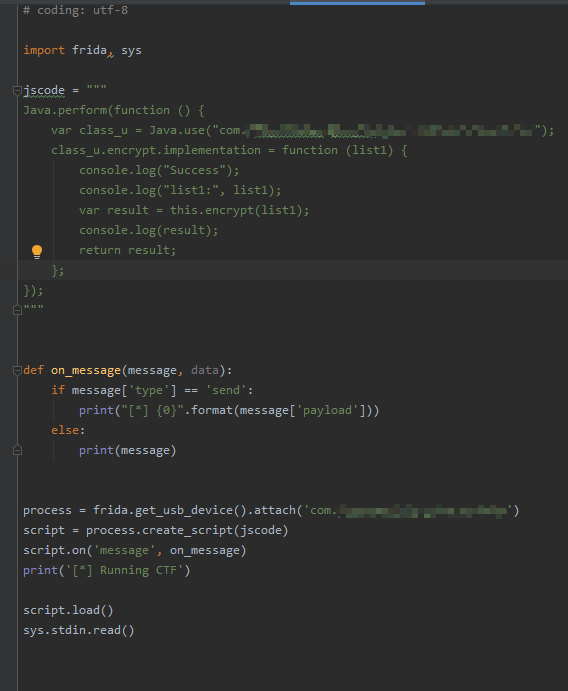
同时来抓包对比:
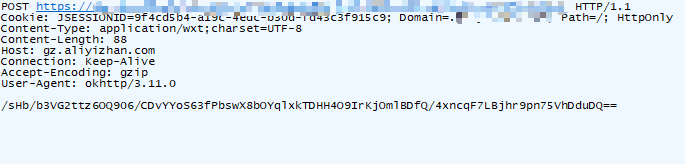

就得到了这里的请求 data 入参数据:
pageIndex:当前页码
pageSize:当前页对应的数据条数
typeId 和 source 是固定的, 接下来再来 hook decrypt 函数,对比抓包和 hook 结果:
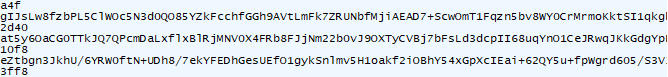

结果是一样的,至此,我们逆向分析就完成了。
总结一下请求和响应过程,就是请求体中的 data 经过 encrypt 函数加密传参,改变 pageIndex 就可以得到每页数据,响应是经过 decrypt 函数加密显示,那我们只需要在 python 中实现这个 aes 加密解密过程就行了,从反编译的 java 代码中可以看出密钥是固定的:wxtdefgabcdawn12,没有 iv 偏移。
请求
直接上代码:

运行代码,成功拿到数据:
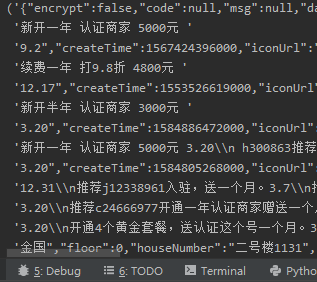
小结
到此这篇关于如何使用PythonAPP逆向抓取数据的文章就介绍到这了,更多相关Python逆向抓取APP数据内容请搜索W3Cschool以前的文章或继续浏览下面的相关文章。



