

HashMap是Java中广泛使用的数据结构之一,它提供了高效的键值对存储和检索功能。本文将深入探讨HashMap的底层原理,包括它的数据结构、哈希算法、碰撞解决方法以及工作原理。
数据结构
HashMap的底层数据结构是数组和链表(或红黑树)。数组用于存储元素的桶(bucket),每个桶是一个链表或红黑树的头节点。当出现大量元素存储在同一个桶内时,链表将转换为红黑树,以提高检索效率。
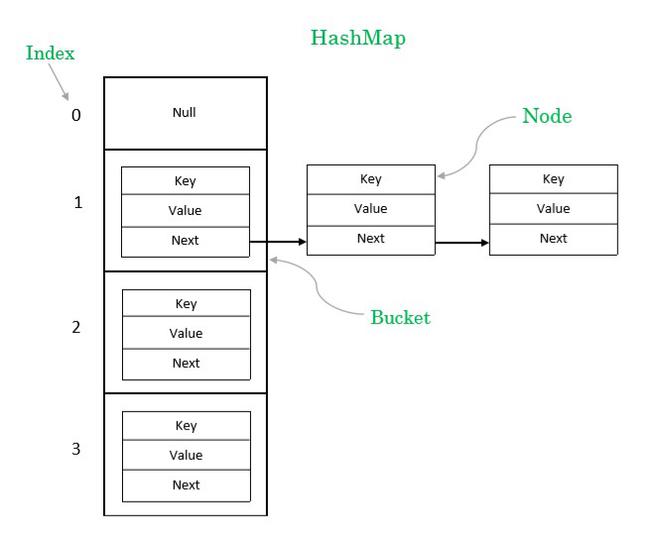
哈希算法
HashMap使用哈希算法将键映射到数组索引位置。哈希算法的关键是hashCode()方法。当调用hashCode()方法时,HashMap会根据键的特性生成一个哈希码。哈希码是一个整数,它代表了键在数组中的位置。
碰撞解决方法
在哈希算法中,不同的键可能会生成相同的哈希码,这就是所谓的碰撞(collision)。HashMap使用链表和红黑树来解决碰撞问题。
当元素被插入到HashMap中时,首先根据键的哈希码计算出数组索引。如果该索引位置为空,则直接将元素插入其中。如果该索引位置已经存在元素,则遍历链表或红黑树,判断键是否已经存在。如果键已存在,则更新对应的值;如果键不存在,则将新元素添加到链表或红黑树的末尾或合适位置。
当链表的长度超过8个节点,并且数组的长度大于64时,链表将被转换为红黑树。这是为了提高在大量元素存储在同一个桶内时的查找效率。
源码
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
工作原理
当使用HashMap进行插入、获取或删除操作时,它会执行以下步骤:
- 根据键的
hashCode()方法计算哈希码。 - 根据哈希码找到数组索引位置。
- 如果该索引位置为空,直接插入元素。
- 如果该索引位置不为空,检查键是否已存在,如果存在则更新值,否则将元素插入链表或红黑树。
- 如果链表长度过长,并且数组长度足够大,将链表转换为红黑树。
- 根据需要调整数组的大小(扩容或收缩)以保持较低的负载因子。
总结
HashMap是一种高效的键值对存储和检索数据结构。它的底层原理基于数组、链表和红黑树,使用哈希算法将键映射到数组索引位置。碰撞问题通过链表和红黑树的使用得以解决。了解HashMap的底层原理对于理解其运作方式、优化性能以及避免潜在的问题非常重要。通过合理选择哈希函数和调整负载因子,我们可以确保HashMap在各种场景下都能够提供高效的数据存储和检索能力。



