

本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
下载W3Cschool手机App,0基础随时随地学编程>>戳此了解
导语
利用简单的机器学习算法实现垃圾邮件识别。
让我们愉快地开始吧~
相关文件
百度网盘下载链接: https://pan.baidu.com/s/1Hsno4oREMROxWwcC_jYAOA
密码: qa49
数据集源于网络,侵歉删。
开发工具
Python版本:3.6.4
相关模块:
scikit-learn模块;
jieba模块;
numpy模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
逐步实现
(1)划分数据集
网上用于垃圾邮件识别的数据集大多是英文邮件,所以为了表示诚意,我花了点时间找了一份中文邮件的数据集。数据集划分如下:
训练数据集:
7063封正常邮件(data/normal文件夹下);
7775封垃圾邮件(data/spam文件夹下)。
测试数据集:
共392封邮件(data/test文件夹下)。
(2)创建词典
数据集里的邮件内容一般是这样的:

首先,我们利用正则表达式过滤掉非中文字符,然后再用jieba分词库对语句进行分词,并清除一些停用词,最后再利用上述结果创建词典,词典格式为:
{"词1": 词1词频, "词2": 词2词频...}
这些内容的具体实现均在"utils.py"文件中体现,在主程序中(train.py)调用即可:

最终结果保存在"results.pkl"文件内。
大功告成了么?当然没有!!!
现在的词典里有52113个词,显然太多了,有些词只出现了一两次,后续特征提取的时候一直空占着一个维度显然是不明智的做法。因此,我们只保留词频最高的4000个词作为最终创建的词典:

最终结果保存在"wordsDict.pkl"文件内。
(3)特征提取
词典准备好之后,我们就可以把每封信的内容转换为词向量了,显然其维度为4000,每一维代表一个高频词在该封信中出现的频率,最后,我们将这些词向量合并为一个大的特征向量矩阵,其大小为:
(7063+7775)×4000
即前7063行为正常邮件的特征向量,其余为垃圾邮件的特征向量。
上述内容的具体实现仍然在"utils.py"文件中体现,在主程序中调用如下:
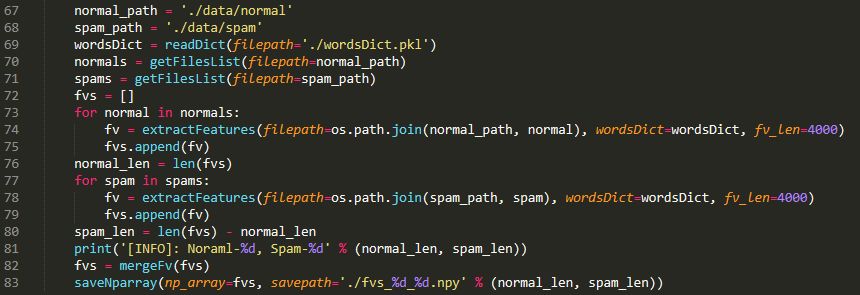
最终结果保存在"fvs_%d_%d.npy"文件内,其中第一个格式符代表正常邮件的数量,第二个格式符代表垃圾邮件的数量。
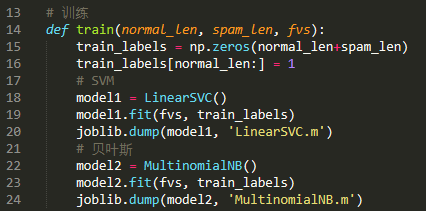
(4)训练分类器
我们使用scikit-learn机器学习库来训练分类器,模型选择朴素贝叶斯分类器和SVM(支持向量机):
(5)性能测试
利用测试数据集对模型进行测试:

结果如下:


可以发现两个模型的性能是差不多的(SVM略胜于朴素贝叶斯),但SVM更倾向于向垃圾邮件的判定。
That's all~
完整源代码请参见相关文件。
更多
没有具体介绍模型原理,因为后续可能会出一个系列,比较完整详细地介绍一下机器学习里的常用算法。所以,就先这样吧~



